
数据结构课设:霍夫曼编码译码
前言
单纯对这类题目比较感兴趣吧,因为要是单纯去实现最原始的霍夫曼算法的话,其实很简单的,但是很多时候正是我们的不知足心理推动了技术的发展与进步,而我也恰恰觉得现阶段霍夫曼算法还有可以优化的地方而变得更加高效,也希望能借这个机会给下学期的算法课开个好头。
题目
问题描述
利用哈夫曼编码进行信息通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。但是,这要求在发送端通过一个编码系统对待传数据预先编码;在接收端将传来的数据进行译码(复原)。对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。试为这样的信息收发站写一个哈夫曼码的编译码系统。
基本要求
一个完整的系统应具有以下功能:
(1)I:初始化(Initialization)。从终端读入字符集大小n及n个字符和m个权值,建立哈夫曼树,并将它存于文件hfmtree中。
(2)C:编码(Coding)。利用已建好的哈夫曼树(如不在内存,则从文件hfmtree中读入),对文件tobetrans中的正文进行编码,然后将结果存入文件codefile中。
(3)D:解码(Decoding)。利用已建好的哈夫曼树将文件codefile中的代码进行译码,结果存入文件textfile中。
(4)P:打印代码文件(Print)。将文件codefile以紧凑格式显示在终端上,每行50个代码。同时,将此字符形式的编码文件写入文件codeprint中。
(5)T:打印哈夫曼树(Tree printing)。将已在内存中的哈夫曼树以直观的方式(树或凹入表形式)显示在终端上,同时将此字符形式的哈夫曼树写入文件treeprint中。
初期设计

文献分析
第一篇
一种空间更优的快速霍夫曼解码算法:
[1]. Chen, H.C., Y.L. Wang and Y.F. Lan, A memory-efficient and fast Huffman decoding algorithm. INFORMATION PROCESSING LETTERS, 1999. 69(3): p. 119-122.
以这棵霍夫曼树为例:
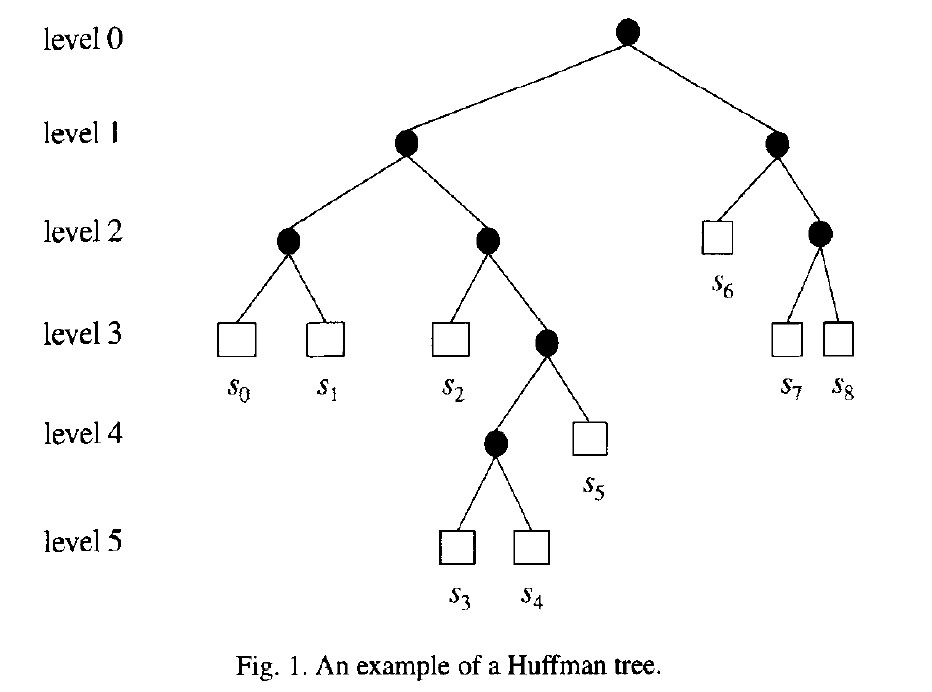
一些定义
各叶子节点从左至右用 表示(共有n个编码元素)
level表示节点所在,级数,根节点级数为0,用 表示
height表示二叉树高度,即霍夫曼树中level的最大值,用 表示
编码元素的weight用 表示(注意这个跟题干里的元素权重或者出现频率是不一样的),
定义 ,(其实这个是不必要的)
那么对于一棵霍夫曼树,我们就可以得到它的的对应的值的表,以上面的霍夫曼树为例:
用三个数组存储相应元素
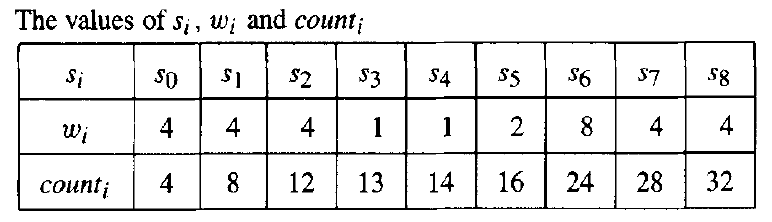
第一种算法
伪代码(算法逻辑)
那么,在对霍夫曼编码进行解码的时候,我们就希望在尽可能短的时间内通过编码获取到对应的元素,算法伪代码如下:
Step1:计算 ,其中是二进制数 的位数,式中的 换算成十进制参与计算
Step2:在的数组中搜索:
- 若没有相应的与 相等,则 不是一个编码
- 若存在,假设
Step3:如果 ,则 不是一个编码,否则 对应的编码元素就是 (相当于找到了元素存储的下标 )
举例
(直接用原文的例子吧,很好理解)

原理
假设有高为 的满二叉树(霍夫曼树),则有个节点(注意这里对的定义其实与课程中讲的并不一样)、个叶子。不妨设各叶子(编码元素)为 ,那么 ,。
那么,对于给定的二进制编码 , 对应的十进制就是对应的 的下标值。
假设高为 的霍夫曼树 不为满二叉树,则级数为 的 的 ,也就是当 是对应的高为 的满二叉树时,该节点作为内部节点的子树的叶子的数量。
在搜索 对应的编码元素时,若 的位数小于 ,则追加足够的1来获得长度为 的二进制串 (其实就相当于补成满二叉树的情况),那么,定义 对应的weight 为 ,则 或 。
显然,若 不在 的数列中,则 一定不是一个元素的二进制编码。若在,但由于我们追加了足够的1去获取长度为 的二进制串,则可能存在多个二进制串对应值为 的weight,所以需要第三步的检验。
复杂度
显然时间复杂度是,相较于使用优先级队列或直接使用队列的有较大提升。
占用的空间则为 ,用于存储三个数列及树的高度 。但是其实至少可以优化到 ,因为 ,所以存储 的数列是不必要的。
第二种算法(改进的算法)
现在的空间占用已经压缩到了 ,我们希望进一步压缩 的占用空间。
令 。若 为奇数,
令 ,且 。
此外,定义一个新变量 ,若 ,则令 ,否则,即 时, 。
由于我们能够通过 数列获取(计算出),所以不必存储 。
伪代码
输入: 的数列、树的高度 以及二进制编码 。
输出: 对应的编码元素
过程:
- Step1:计算 ,其中是二进制数 的位数,式中的 换算成十进制参与计算
- Step2:找到 ,使得 。
- Step3:计算 。
- Step4:分解 为 ,使得 对于非负整数 ,不失整体性地假设
- 该分解可以如下进行:判断 是否等于 ,若不相等,那么 , 。否则,
- Step5:用 计算出 相应的
weight- 其实应当注意到,对应,。
- 对应地易解以及(也就是 的形式)
- Step6:若 且 ,那么 对应的编码元素就是 。令 ,并终止算法。
- Step7:若 且 ,令 ,并终止算法。都不满足,则 不是一个编码。
举例
还是以上面的霍夫曼树为例
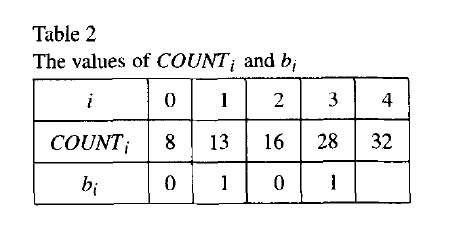
- 。
- 第一步, 。
- 第二步,,。
- 第三步,。
- 第四步,。
- 第五步,
- 第六步,,,则 对应的编码元素是
原理其实是跟上面的算法一样的,只不过这里没有存储并且将进行了两两归并。
复杂度
时间复杂度仍为 。
空间复杂度,数列 以及树的高度 的空间复杂度分别为 ,总共的空间复杂度就是这四项的和。
即:
第二篇
[1]胡丽莹,林鹭.一种基于多级查找表的高效Huffman编码算法[J].数学杂志,2012,32(04):753-760.DOI:10.13548/j.sxzz.2012.04.028.
文中扩展霍夫曼树和分级存储的思想对我的霍夫曼树的存储方式有较大启发。
该文中通过对树进行分级并定义偏移量来提高传统查找表的数据存储效率,但实际上原文中构建多重查找表的过程中使用的仍然是一个时间复杂度 的算法(更严格的说是近似 的算法, 为树的高度。这就导致虽然在空间复杂度上实现了优化,但也付出了一定的时间复杂度的代价,是一种以时间换空间的方法。
但其实在霍夫曼树中,真正有效的数据其实就是叶子元素(原始字符与其编码)及他们的位置。所以完全可以通过将树补满后记录各个叶子节点的位置和内容,在恢复霍夫曼树时通过叶子节点自底向上完成构建。
基于这种思想我完成了对叶子节点的数据保存策略,在综合开发-逻辑层-初始化-叶子节点的定位策略部分给出了分析。
第三篇
[1]文国知.基于C语言的自适应Huffman编码算法分析及实现研究.武汉工业学院学报,2011,30(2):53-57+62.
通过C语言程序,动态统计信源符号概率,逐步构造Huffman编码树,实现了自适应Huffman编码,解决了静态编码树不能根据信源符号的局部变化做出相应变化的主要问题。结果表明,自适应Huffman编码算法压缩率很大,能进一步提高数据传输的效率。
这篇文献关注的是课程设计的初始化和编码两个功能。
Huffman编码算法进行编码时,必须进行两次扫描,第一次扫描统计字符出现的概率(权重),并据此进行构造Huffman树;第二次扫描是按Huffman树的字符进行编码。
虽然题目中给出的条件允许输入各节点的权值,但在实际应用过程中是不现实的。
而自定义哈夫曼编码,预先不知道各种符号的出现频率,编码树的初始状态只包含一个叶节点,即NYT(Not Yet Transmitted),NYT是一个溢出码,不同于任何一个将要传送的符号,当一个尚未包含在编码树中的符号需要被编码时,首先输出NYT的编码,然后跟着符号的原始表达。当解码器解出一个NYT之后,它就知道下面的内容暂时不再是Huffman编码,而是一个从未在编码数据流中出现过的原始符号。当插入一个符号q时,会出现两种情况:
- q是第一次出现的字符结点。构造一个新的子树,子树包含NYT符号和新符号两个叶节点,如下图所示。然后判断该子树的父节点是否是是当前权重下编号最大的结点,如果是,直接更新权重即可;否则,将父节点与相同权重的编号最高的结点交换,再更新权重值。
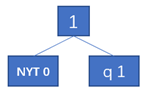
- q不是第一次出现的字符结点。如果q所在节点,是当前节点权重下编号最大的结点,则直接使其当前节点权重及父节点权重加1即可。否则,将当前节点与相同权重的编号最高的结点交换,再更新权重值。
通过这种方式可以在进行编码的同时构建霍夫曼树并获取到相应编码,提升程序运行效率。
但是存在的最主要的问题是其编码与采用普通霍夫曼编码所得的编码序列并不一致,所以无法采用这种方法直接获取到可解析的霍夫曼编码(其实如果需要解析还是需要依据这棵编码树的动态调整,效率相对较低)。
(其实这种方法最大的问题在于获取到的编码与普通霍夫曼编码所得的编码序列并不一致,所以还要重新编码)
第四篇
[1]李伟生, 李域, 王涛. 一种不用建造Huffman树的高效Huffman编码算法[J]. 中国图象图形学报, 2005, 10(3):382-387.
由于题目中明确要求构建霍夫曼树且该文算法其实是一个 的算法,故未采用,但其原理确实有趣,也对我的代码逻辑有一定启发。尤其是文中大部分前提都是由满二叉树演进到霍夫曼树,给我的整体代码逻辑与推理提供了很大启发。
综合开发
逻辑层
类与结构体
1 |
|
初始化:
通过自适应霍夫曼编码对获取到的字符序列进行编码,直接完成初始化,不必读入权值。编码后对霍夫曼树进行压缩发送(将所有非叶子节点全部剪掉而仅保留有效信息),使视图层能通过接收到的霍夫曼树的信息进行重建霍夫曼树。
获取霍夫曼编码的策略:
使用栈,由叶子节点循环向父节点移动,若当前节点是父节点的左孩子则向栈中加入0,否则加入1,结束后将栈内容依次pop即可。(相当于完成了一次字符串反向输出,时间复杂度)
查询策略:
动态编码时常常要查找某字符是否已经编码过,若使用线性结构存储已经编码的元素则总体编码的时间会达到 (为字符个数, 为总的字符长度)。
为此,使用unordered_map替换线性表,可将这一部分时间杂度降低到 。
但由于更新一个节点权重的时间复杂度在 到之间(如果不用调换子树与节点位置则复杂度为 ,但可能存在调换子树与某一节点位置并更新编码的情况使得复杂度大于这个值但小于 ),所以总体的时间复杂度仍介于 到之间。(也可以表示为, 为调换的次数,通常来说 小于 )。
节点的定位策略:
对于任意霍夫曼树 ,定义其对应的满二叉树为 。
定义树的级数为 , 为树的高度。(避免“级数是从1开始算”的误解)。
定义两节点之间的落差 (drop)为两节点的级数 (level)之差的绝对值,也即
用 代表某一节点在 中所在级数的位置(从左到右为 ~ )
对于任意的一个编码,编码的长度其实就是该叶子节点在树中的级数,编码从头到尾的过程也就是从霍夫曼树根节点到编码元素叶子节点的过程。
那么如何计算 :相对偏移量累加
定义两节点间的相对偏移量 , ,依据编码,指针从根节点开始,若下一节点是当前节点的右子树,则累加当前节点与叶子节点间的相对偏移量,并将指针移向下一个节点。重复这个步骤,直至当前指针指到叶子节点。
如:
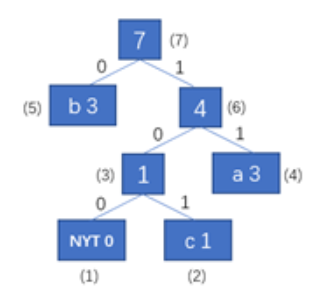
对于节点(2),编码101,,,也就是说,该叶子节点是树中第四级第六个节点(如果认为根节点算第一级)。
那么,该节点的定位
不足:
- 每次更新编码都要在
unordered_map里更新一遍对应编码,造成一定的时间浪费。 - 在增加节点权值是出现调换子树与某一节点位置后要更新节点的霍夫曼编码,增加权值与更新节点的霍夫曼编码的复杂度都为 ,遍历无序哈希表为所有已编码元素更新编码的时间复杂度为 ,使得整个过程复杂度为,但其实并不是所有的编码都需要更新,所以仍然可以优化。
- (其实这里被迫遍历是因为编码采用了无序哈希表存储,但若采用有序表存储,在更新时仍要涉及元素的查找,也至少是的时间复杂度,所以可优化的空间并不是很大)
编码:
编码过程可以直接使用初始化时形成的无序哈希表,使得整体的时间复杂度为 。但由于编码的存储形式都是字符(串),所以还需要将字符串转化成数字。
方案一:
Unsigned long long的数值范围是0~18446744073709551615 (2^64 - 1),可以将编码后的数字转化成Unsigned long long存储,每个数字占用8字节空间,不过存在开头是0而被省去的情况,但只要严格按照每20位存为一个数,只要在被省去的位置补0就可以了。
方案二:
可以对编码进行二次编码。即每四位转换成一个16进制数存入数组,但可能存在末尾不足四位的情况,用数组的第一个数字(0,1,2,3)直接记录最后末尾的位数,然后用0补足空位进行转换。在解码时再转换回二进制数即可。由于一个十六进制数只占半个字节,所以也可以节省很多空间。
综合来看方案二更优:每20位,方案一占用8字节,方案二占用2.5字节。(相较之下,如果不转换成数字再进行压缩,那么每个char就要占用1字节)
问题:
但其实,在txt文件(文本文件)中,每个字符都会占用一个字节,也就是说,并不会如我们所期望的那样存储为数字,所以如果想应用上面的两种方案,那么结果就必须写入一个二进制文件,但是问题在于二进制文件是无法直接打开可读的,而且可能需要自己设计文件格式以保证性能,所以有没有一种折中的方案呢?
(两种文件区别,参考)
方案三:
对于编码所得的二进制字符串,每八位0,1为一个字符,存储成ASCLL 字符,在解码时再将这些字符串解析为八位二进制串,这样其实也是相当于字节的每一位都存储了一个0/1的值
1 | //编码 |
(这里使用哈希表实现了一个近似 的解码,也可以使用霍夫曼树实现 的解码)
解码:
若采用第一篇文献的算法,时间复杂度 ,空间复杂度
但其实,如果也采用unordered_map,即将获取到的霍夫曼树的所有叶子按照编码为 ,字符为 组成 unordered_map,可以将时间复杂度降到接近 ,空间复杂度为 。但在创建表的时间复杂度为 。
或者,直接采用霍夫曼树进行解码,时间复杂度是
IO:
使用的IO是ifstream与ofstream,并没有针对读写文件进行优化,但其实虽然在读文件 上ifstream效率并不算太低,但写文件的ofstream绝非最佳选择,但为了方便还是选用了,所以IO还有一定的优化空间。
存在的问题:
存在读取中文为乱码的问题,网上给出了一些解决方案。
最简单的方法是将文件格式改为ASCI(其实``ofstream输出的文件编码就是ASCI`),也可以根据不同编码格式进行不同读取
1 |
|
经过测试,我这里UTF-8输出的p是59042经过转换是0xe6a2,这里大家可以再进行一下测试
直接读取utf-8:
1 |
|
————————————————
参考:https://blog.csdn.net/qq_36437446/article/details/105279221
改进:
感觉上面的办法很麻烦,最后选择使用getline()的循环来获取所有字符,并用string作为读入类型替代了原先的逐字节(char)读取,因为显然255的长度是肯定无法编码所有汉字的。初始思路是getline()之后调用substr(i,1)对字符串进行依次分割,但发现仍有乱码。
乱码原因在于中文采用三个字节进行编码,而substr(i,1)只会截取一个字节长度的子串,所以在读取到中文时需要substr(i,3)。将字符串用%x格式打印出来,可以发现中文的字符的char值都是0xffffffe6这样的,而非中文字符则是0x2e,0x61这样。所以只需要在一个循环中从开头开始比较字符值,大于0xffffff80(或者大于0x80也行)的值则下标+3,否则下标+1,即可保证汉字始终被完整截取。注意0xffffff80是一个负数,需要先转为unsigned int再比较大小。
1 | vector<string> getEachString(const string& s){ |
树的重建:
树重建的主要问题在于如何在更低的时间复杂度内确定节点的widget,主要思路也无非自顶向下构建和自底向上构建两种,如果选择自底向上构建,问题在于无法直接通过子节点知道其真实对应的父节点是否存在,那么就需要额外的针对某种key与节点的存储,利用key存在与否判断节点是否存在。
这个key并没有选用num,是因为子节点与父节点之间的num并无关系,无法通过数学逻辑进行互推。受第二篇文献启发,我使用 locate 按层由上向下依次对满二叉树进行编码,即 ,其中l为level,都可以由节点属性直接获取,作为key进行标识节点是否存在,这个标识在视图层也会用到。
基于n的特点,可以直接确定,若n为偶数则为父节点的左子树(0认为是偶数),否则则为父节点的右子树。通过这种方式确定子节点与父节点的左右子树关系。
这样,只要对所有叶子节点自下向上遍历一遍,依次建立父子关系即可完成树的重建。
如果在重建树的同时进行weight的计算,一方面,操作间的耦合度增加导致维护困难,另一方面,由于采用自底向上构建的方法,导致增加节点的时候可能存在树并不连通的情况导致某些上层节点的weight未被增加,所以选择在完成树的节点重建后,单独遍历叶子集合,自底向上完成遍历与weight的增加。
视图层
树的重建
视图层由于并没有指针类型,无法通过链表进行构建,最终选择模拟指针,但就需要对节点的唯一定位标识作为模拟指针的值,所以仍然沿用逻辑层中locate的概念,作为模拟指针值。
在存储形式上,仍选用unordered_map使用<int,Node*>的泛型进行存储。
优化:及时终止
在逻辑层与视图层都做了优化,考虑到每个节点到根节点只有唯一一条路径,那么对所有叶子节点,在想根节点遍历的过程中,若发现某节点的父节点已经存在,则必有一次遍历已经建立了该节点到根节点的唯一路径,可直接结束,执行下一个叶子节点的遍历。
树的可视化
这部分写在我的博客:绘制:霍夫曼树
中间层
这部分写在我的博客:mix-code_flutter-cpp
测试、总结
测试
时间统计:QueryPerformanceCounter()(逻辑层时间)
压缩率基本维持在60%到80%
| 文件 | 大小 | 时间 | CPU占用(共16G) |
|---|---|---|---|
| 1 | 195字节 | 0.0130425s | |
| 2 | 7.44K | 1.79969s | 19% 1% (3.04G 0.16G) |
| 3 | 28K | 7.3096s | 27% 1% (4.32G 0.16G) |
| 4 | 397K | 139.738s | 24% 3% (3.84 0.48G) |
总结
经验与不足
ifstream和ofstream在读取中文文件时并不能做到很好的适配,同时其ASCI的编码格式导致在开发过程中需要考虑一定的编码问题(一般常用的编码都是utf8)。最要命的是不支持中文路径。
getline()和substr()对于中文编码适配也不好,与中文的编码格式有关。
总而言之,IO较佳的读写方案是使用FILE类进行操作,能避免很多问题。
最大的不足在于初始化霍夫曼树时使用了过多指针导致性能过低
应该采用哈希表与模拟指针解决这一问题,能够极大地提高程序运行效率。
其次,文件读写更推荐使用二进制文件进行读写,使用文本文件读写在读出时会遭遇一系列问题,唯一的优点是可以直接可视化。
如无特殊需求,建议使用二进制文件。
其他:
- 涉及IO仍然较多,导致一定的性能瓶颈
- 局限性较大:只能压缩文本
- 初始化霍夫曼树的复杂度较高导致了程序耗时较长(初始化霍夫曼树的时间占了总时间的95%以上)
- 视图层与逻辑层之间的交互效率比较低导致在使用UI界面时体验不佳(与中间层的调度有一定关系)
- 耦合度过高导致的维护困难,导致难以将指针重写成哈希表。
更进一步:
以上的所有内容算是完成了课设内容,但我对自己完成的程序的压缩效率觉得特别不满意,在查阅一些资料后针对现有的问题重写了一部分代码。
解决的问题:
ifstream和ofstream在中文内容与中文路径上不适配的问题,使用FILE代替- 过多指针导致的效率低下,使用哈希表和模拟指针代替
- 局限于文本文件的编码导致实际上只完成了编码而没有完成压缩,不能压缩常见的二进制文件(如png),使用读写二进制文件代替。
时间紧张没有做的部分:
- 霍夫曼树的可视化和完整的UI界面,所以也没有再像上面那样从满二叉树的视角去看待霍夫曼树
一些不足:
- 霍夫曼编码部分仍然使用了传统的编码思路,即:遍历获取权重->建立霍夫曼树->编码,导致一个文件要读取三遍。
- 省略了很多霍夫曼树的细节如树高和节点位置的标记,使得整棵树难以做高效的可视化。
- 二进制文件中其实有很多冗余信息(不必要的占位),使得在压缩小文件时效率并不高
二进制文件格式:
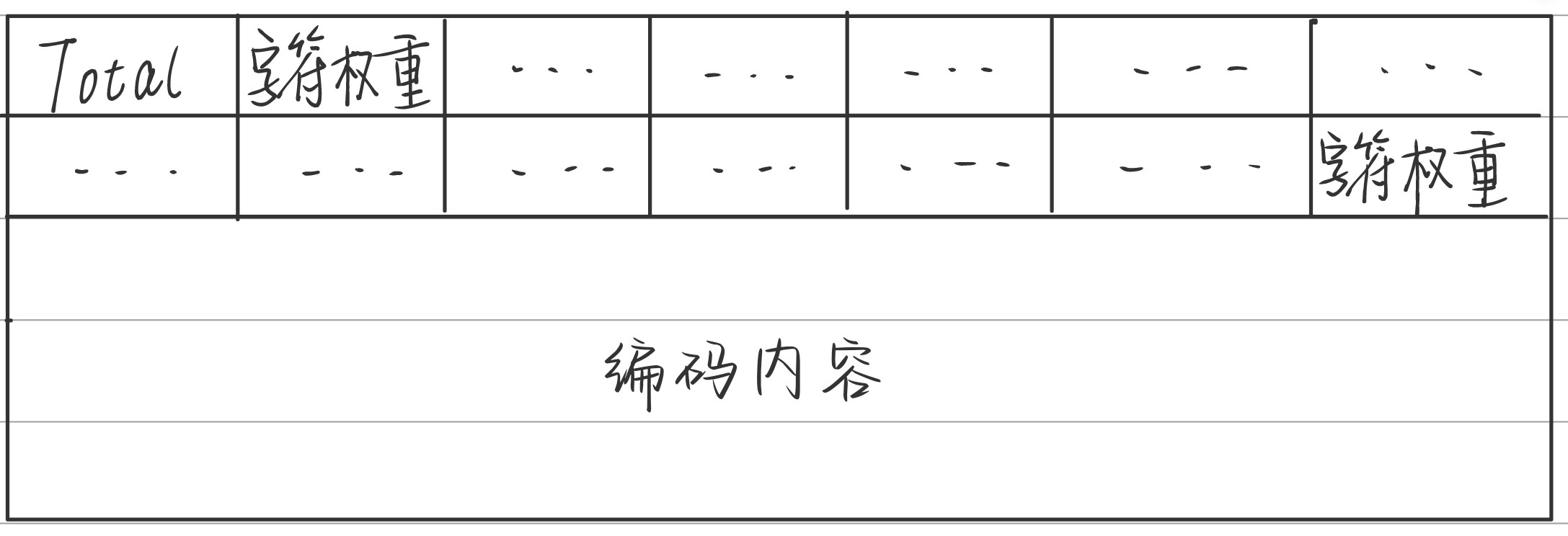
测试
| 文件 | 大小 | 时间 |
|---|---|---|
| 1 | 195字节 | 0.0005313s |
| 2 | 7.44K | 0.0119407s |
| 3 | 28K | 0.0070038s |
| 4 | 397K | 0.104739s |






