
读paper12-静态警报自动确认
读paper12-静态警报自动确认
基于历史缺陷信息检索的语句级软件缺陷定位方法
一个比较有创新性的点是
通过分析类的 AST 可以获取到与此语句相关的 AST 片段,依次提取 AST 片段中的节点类型信息,组成语句的结构信息序列,使用最短编辑距离 (edit distance) 计算两个结构信息序列间的相似程度
编辑距离指的是在两个单词之间,由其中一个单词转换为另一个单词所需要的最少单字符编辑操作次数。
所以相当于将图相似度问题转化为了序列的相似度问题。
基于路径语义表示的静态警报自动确认方法
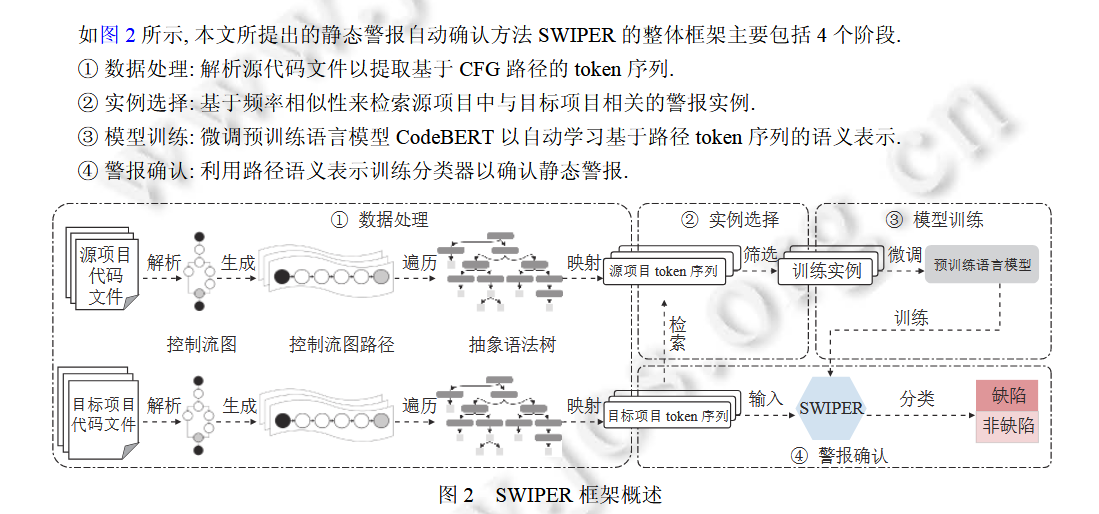
整体流程如上图,比较关键的两个步骤是:
- 基于 CFG 路径的 token 序列的提取
- 基于路径token序列的语义表示的学习
基于 CFG 路径的 token 序列的提取
基本步骤如下:
通过静态分析工具 DTS (defect testing system)将源代码文件解析为 CFG
利用面向目标的路径生成算法生成从入口节点到缺陷节点的 CFG 路径
对于CFG路径的节点,选取两种类型的路径节点进行 token 提取. 第 1 类节点是所有包含警报 IP 处导致潜在缺陷的变量 (称为 IP 变量) 的路径节点. 第 2 类节点是所有包含对 IP 变量存在影响 (如定值-引用关系) 的其他变量的路径节点. 每个路径节点及其包含的原子指令都可以进一步与对应的一个或多个 AST 节点相匹配
用中序遍历对生成路径对应的 AST 节点进行遍历生成token序列
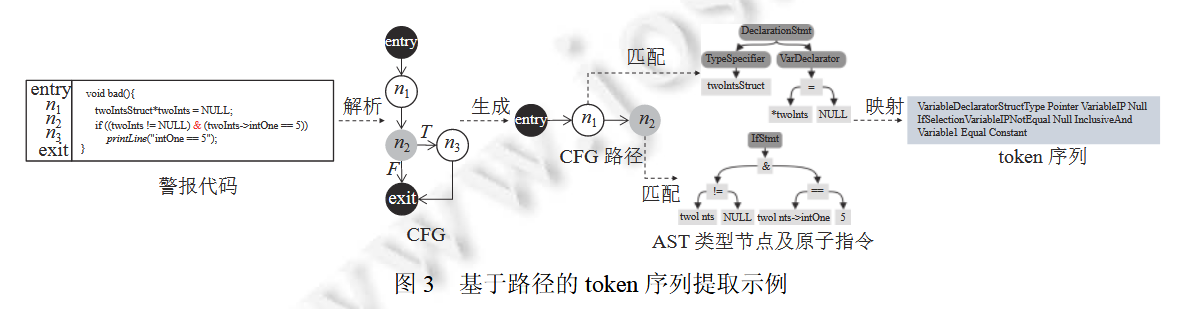
一些细节处理:
- 对自定义变量使用掩码:相同的函数名在不同的项目中实现的功能可能不一致,所以不使用具体的函数名作为 token,而是使用两种函数调用类型 (即库函数调用和用户自定义函数调用) 作为 token 来表示函数调用语句节点。对于代码中出现的变量的抽象,使用一个整数索引 (索引范围从 1 到 N) 来区分不同的变量.
根本上,也是将图问题转换为了序列问题。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 ZWN's blog!
相关推荐






评论


